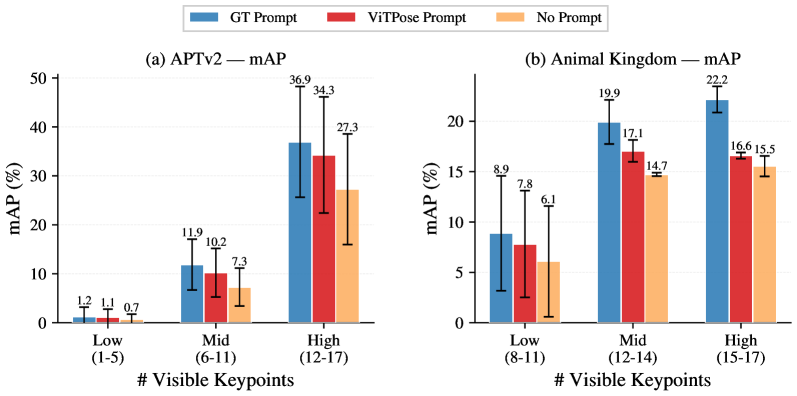
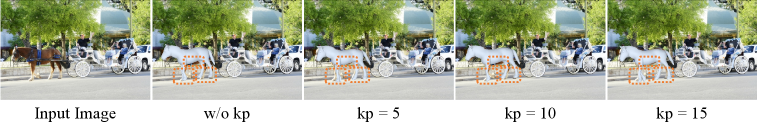Method Overview
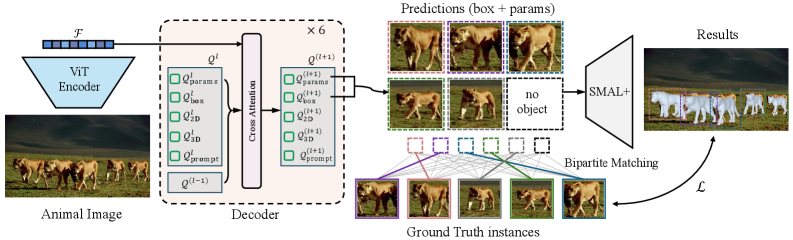
Given a full image, SAM 3D Animal uses a ViT-Huge encoder to extract visual tokens and a SAM-style promptable Transformer decoder to predict SMAL+ shape, pose, camera, and bounding boxes for every animal instance. Unlike SAM 3D Body, which reconstructs one prompted human per forward pass, our model adopts a set-prediction paradigm with DETR-style bipartite matching and predicts up to P = 30 animals at once. Optional keypoint prompts provide skeletal alignment cues, while mask prompts sharpen silhouette discrimination when animals overlap.